
2人のLambdaユーザーの物語
物語#1:アマチュア
一瞬すべてが元気で、それから…バム!Lambda関数で例外が発生すると、警告が表示され、すべてが即座に変更されます。
重要なシステムが影響を受ける可能性があるため、根本的な原因をすばやく理解することが重要です。
さて、これはCloudWatch Logsをスクロールして純粋に手動でエラーを見つけることができる少量のLambdaではありません。したがって、代わりにCloudWatch Insightsにアクセスして、ロググループでクエリを実行し、エラーをフィルタリングします。
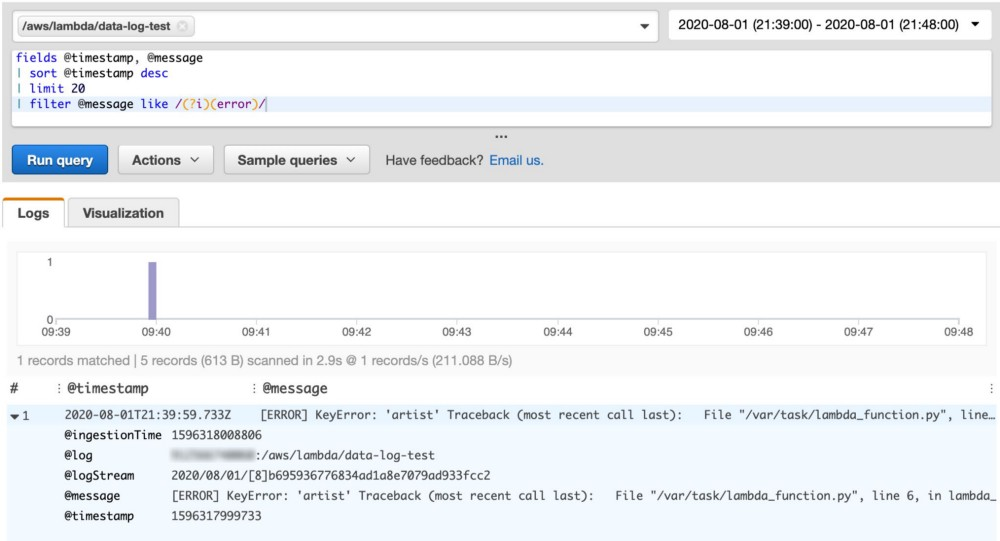
エラーに対するCloudWatch Insightsクエリのフィルタリング
エラーが見つかりました。役立ちますが、残念ながら、失敗した呼び出しに関連する他のログメッセージはすべて省略されます。
上記の情報で、たぶん—たぶん—根本的な原因が何であるかを理解できます。しかし、たいていの場合、自信はありません。
何が起こったのかわからないことや、問題が再発した場合は調査にもっと時間をかけることを人々に伝えますか?かのように!
そのため、代わりにCloudWatch Logsログストリームに移動し、レコードを関連するタイムスタンプまでフィルタリングして、ログメッセージを手動でスクロールして、特定のエラーが発生した呼び出しの完全な詳細を見つけます。
解決時間: 1〜2時間
ラムダエンジョイメント使用指数:低
物語#2:
プロフェッショナル
同じラムダ関数、同じエラー。しかし、今回はロギングとエラー処理が改善されています。タイトルが示すように、これにはprint()ステートメントをより良いものに置き換えることが含まれます。
とにかく、このLambda関数はどのように見えますか?まず、専門家にとってエラーデバッグがどのように見えるかを確認してから、コードを見てみましょう。公正ですか?
ここでも、Insightsクエリから始めます。
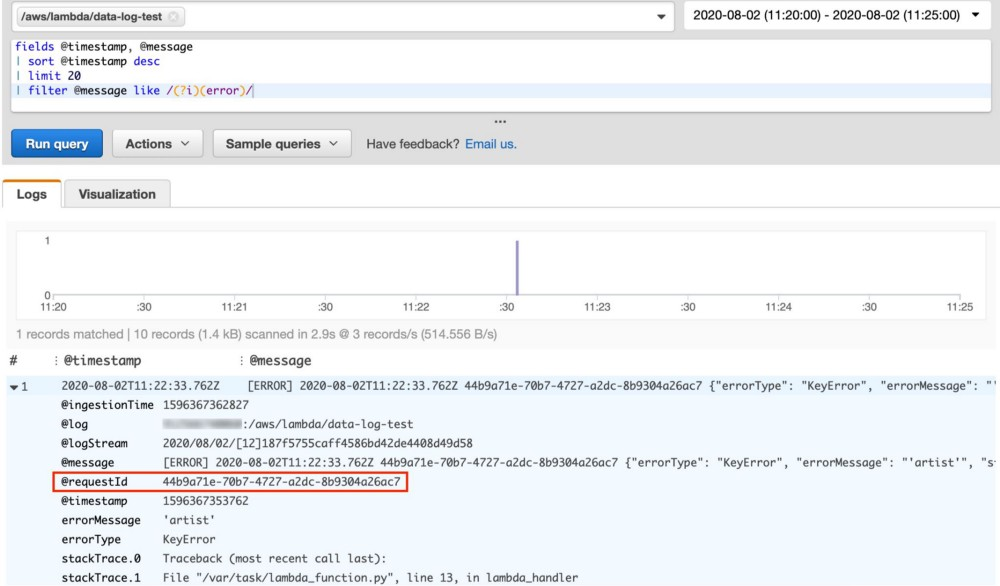
CloudWatch Insightsクエリ、エラーのフィルタリング
また、ログでエラーが見つかりましたが、前回とは異なり、ログイベントに@requestIdはLambda呼び出しからのが含まれています。これにより、2番目のInsightsクエリを実行し、そのrequestIdでフィルタリングして、関心のある正確な呼び出しのログの完全なセットを確認できます。
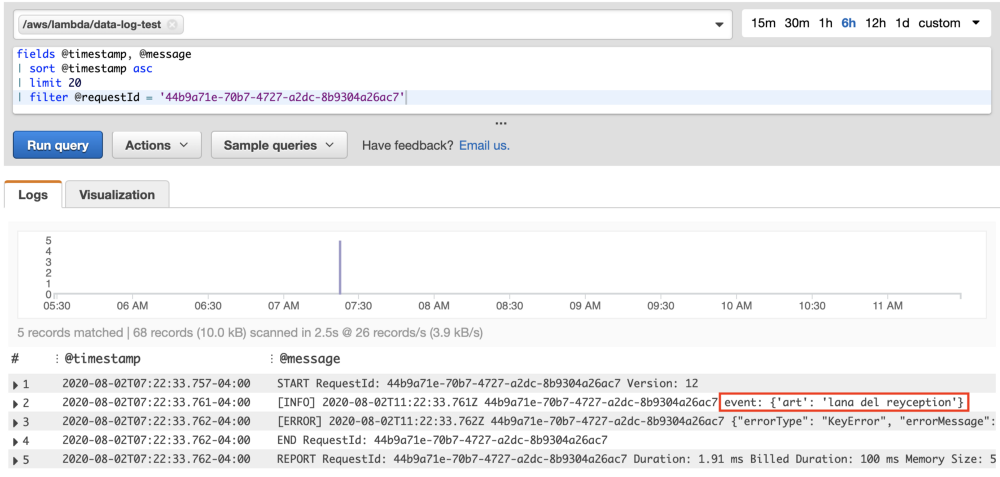
これで、5つの結果が得られました。この結果は、このリクエストで何が起こったかを示す犯罪現場の全体像をまとめて示しています。最も便利なのは、ラムダをトリガーするために渡された正確な入力をすぐに確認できることです。これから、精神的に何が起こったかを推測するか、デバッグするまったく同じ入力イベントを使用してLambdaコードをローカルで実行できます。
解決時間: 10〜20分
Lambdaエンジョイメント使用インデックス:高
コードが明らかにする
読者が席の端にいて、上の話からアマチュアとプロのコードの違いを知りたがっていると想像したいのですが。
それが本当かどうかに関係なく、ここにアマチュアラムダがあります:
def lambda_handler(event, context):
'''Simple Lambda function. event = {'artist': 'Lana Del Rey'}
'''
try:
print(f'event: {event}')
artist = event['artist']
print(f'The artist is: {artist}')
return {"status": "success", "message": None}
except Exception as e:
raise e
もちろん、説明のために意図的に単純にしています。エラーはartist、キーなしでイベントディクショナリを渡すだけで生成されましたevent = {'artisans': 'Leonardo Da Vinci'}。例:
次に、同じ基本機能を実行しますが、print()ステートメントとエラー処理が改善されたProfessional Lambda について説明します。
import sys
import logging
import traceback
import json
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
'''Simple Lambda function.'''
try:
logger.info(f'event: {event}')
artist = event['artist']
logger.info(f'The artist is: {artist}')
return {"status": "success", "message": None}
except Exception as exp:
exception_type, exception_value, exception_traceback = sys.exc_info()
traceback_string = traceback.format_exception(exception_type, exception_value, exception_traceback)
err_msg = json.dumps({
"errorType": exception_type.__name__,
"errorMessage": str(exception_value),
"stackTrace": traceback_string
})
logger.error(err_msg)
面白い!では、なぜロギングモジュールを使用し、例外トレースバックをフォーマットするのでしょうか。
素敵なラムダロギング
1つ目は、Python用のLambdaランタイム環境に、スマートに活用できるカスタマイズされたロガーが含まれていることです。
デフォルトでは、すべてのログメッセージにが含まれるフォーマッタを備えていaws_request_idます。これは、Insightsクエリを可能にする重要な機能であり、上記のように、個々のをフィルタリングして、@requestId1つのLambda呼び出しの完全な詳細を表示します。
例外的な例外処理
次に、おそらく、派手なエラー処理に気づいているでしょう。威圧的に見えますが、Pythonでの例外に関する情報を取得sys.exec_infoする標準的な方法はを使用することです。
例外の名前、値、スタックトレースを取得した後、jsonダンプされた文字列にフォーマットし、3つすべてが1つのログメッセージに表示されるようにします。キーは自動的にフィールドに解析されます。これにより、複雑な文字列の解析を必要とせずに、特定のエラーに基づいてカスタムメトリックを簡単に作成できます。
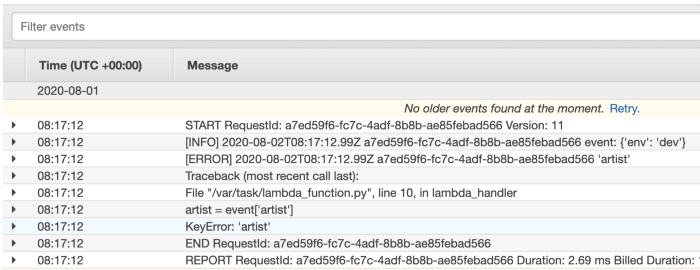
最後に、対照的に、フォーマットせずにデフォルトのLambdaロガーで例外をログに記録すると、不幸な複数行のトレースバックが次のようになることに注意してください。
まとめ
あなたのLambda関数が現時点でアマチュアLambdaに似ているとしたら、この記事があなたのダンスをアップグレードしてProに移行するきっかけとなることを願っています。
先に進む前に、printステートメントを適切なロギングに置き換えることのマイナス面は、Lambdaのローカル実行から生成された端末出力が失われることです。
これを回避するには、環境変数またはあるlambda_invoke_local.pyタイプのファイル内のいくつかのセットアップコードを使用する巧妙な方法があります。
興味があればお知らせください。詳細については、今後の記事で説明させていただきます。
最後に、最後のひらめきとして、Cloudwatch Insightsクエリを実行して自分でデバッグする代わりに、「アラーム中」の状態のときにSNSトピックに通知するLambda Errorsメトリックに対してアラームを設定できるようにする必要があります。次に、別のLambdaがそのSNSトピックをトリガーして、Proと同じデバッグInsightsクエリを自動的に実行し、関連するログをSlackなどに返します。
かっこいいでしょう?
ポール・シングマン
variis.comのシニアMLエンジニア| データと個人の成長に焦点を当てています。
