お住まいの地域の住宅価格についての洞察を得ようとしているデータサイエンスの学生や不動産業者向けの、Pythonの経験がある方のためのチュートリアル。
不動産業者は、住宅が何をどれだけ売るかを知るのに一生の経験が必要です。多くの場合、経験の浅い売り手または買い手は、古いプロにとって明らかな何かを見逃す可能性があります。
この演習では、住宅の最終的な販売価格を予測する際に焦点を当てるのに最も重要なものはほとんどない、住宅のあらゆる側面を説明する79の説明変数から試してみます。
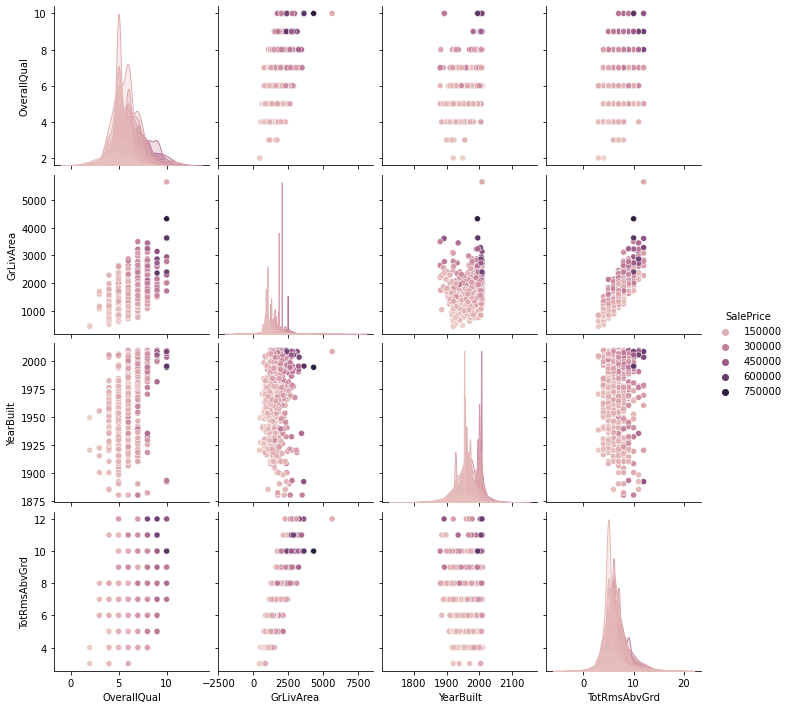
ほとんどの場合、結果は私たちが期待するものであり、より大きな新しい家や最近改装された家はより多くを売ります。しかし、寝室が多すぎる場合や、暖炉が複数ある場合はどうでしょうか。最も重要な機能とその制限を知ることは、住宅市場の誰にとっても重要であり、これらの手順に従うことで、あなたはあなたの財産を分析して、質問や多額の支出を避けるためにどこに落ちるべきかを知ることができます。
データセット
このデータセットはアイオワ州のKaggleAmesコンテストからのものですが、すべての手法は任意の数の観測または特徴に等しく適用できます。
I.データのロードとクリーンアップ
#パッケージをインポートし、完全なデータセットをロードします
%matplotlibのインライン
インポート警告
のNPとしてインポートnumpyの
PDのような輸入パンダ
海としてインポートseaborn
PLTとしてインポートmatplotlib.pyplot
sklearn.imputeインポートSimpleImputerから
sklearnインポートデータセット、linear_modelから
sklearn.linear_modelインポートロジスティック回帰から
sklearn.model_selectionインポートtrain_test_split、GridSearchCVから
からsklearn.linear_model import LinearRegression、Ridge、Lasso、ElasticNet
from sklearn.ensemble import RandomForestRegressor、GradientBoostingRegressor
from sklearn.neighbors import KNeighborsRegressor
#警告を無視するwarnings.filterwarnings
( 'ignore')
#データ
トレインをロード= pd.read_csv( 'train.csv')
欠測データを確認する
#欠落を確認します:
missingData = train.isnull()。mean(axis = 0)
#remove
は30%より大きい
#indexであり、列名にmissingIndex = missingData [missingData> 0.3] .indexmissingIndexを
指定します
#データの作業コピーを作成する
workingDf = train.copy()
workingDf.isna()。sum()。loc [workingDf.isna()。sum()> 0] .sort_values()
データが欠落しているフィーチャを出力します。
Index(['Alley'、 'FireplaceQu'、 'PoolQC'、 'Fence'、 'MiscFeature']、dtype = 'object')
電気1
MasVnrType 8
MasVnrArea 8
BsmtQual 37
BsmtCond 37
BsmtFinType1 37
BsmtExposure 38
BsmtFinType2 38
GarageCond 81
GarageQual 81
GarageFinish 81
GarageType 81
GarageYrBlt 81
LotFrontage 259
FireplaceQu 690
フェンス1179
アリー1369
MiscFeature 1406
PoolQC 1453
DTYPE:int64モード
欠落しているデータの多くは、プールや暖炉などがないという理由だけであることが多いため、NULLを0や「プールなし」などの機能に置き換えることができます。次のようなものを使用して、機能ごとにこれを実行します。
#PoolQCからNAを削除
workingDf.loc [pd.Series(workingDf.PoolQC.isna())、 'PoolQC'] = 'NoPool'
一部の機能は相関性が高く、値が欠落している場合があります。散布図のようなもので、疑わしい特徴との相関を確認してください。たとえば、LotFrontageには多くのデータがありませんが、LotAreaの合計と相関していると思います。
#間口と区画面積を比較してください!
lotFrontageByArea = workingDf [['LotFrontage'、 'LotArea']]
plt.scatter(np.log(workingDf ['LotArea'])、np.log(workingDf ['LotFrontage']))
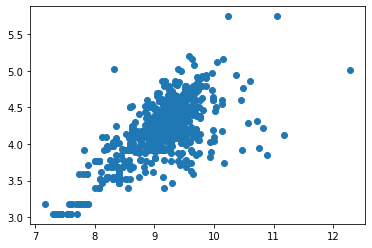
相関性が高いように見える
ここで、相関フィーチャから欠落データを入力するために、2つのモデルを作成し、それらを欠落と非欠落に分割してから、欠落値を予測して再結合できます。
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LinearRegression、Ridge、Lasso、ElasticNet
lotByAreaModel = linear_model.LinearRegression()
lotByAreaModel.fit(lotFrontageNoNa [['LotArea']]、lotFrontageNoNa.LotFrontage)
行方不明に#Spintなく欠落
workingDfFrontageNas = workingDf [workingDf.LotFrontage.isna()]
workingDfFrontageNoNas = workingDf [ 〜 workingDf.LotFrontage.isna()]
#データフレーム
workingDfFrontageNas.LotFrontage = lotByAreaModel.predict(workingDfFrontageNas [['LotArea']])を使用する必要があります
#リストを連結する必要があります!!!
workingDfImputedFrontage = pd.concat([workingDfFrontageNas、workingDfFrontageNoNas]、axis = 0)
次に、カテゴリ機能をダミー化する必要があります。場合によっては、これによりデータセットが非常に「広く」なる可能性がありますが、これから使用するほとんどの回帰では問題ありません。
#今すぐダミー、workingDummies
workingDummies = workingClean.copy()
workingDummies = pd.get_dummies(workingDummies)
print(workingDummies.shape)
workingDummies.head()
print(workingDummies.isna()。sum()。loc [workingDummies.isna()。sum()> 0] .sort_values(ascending = False))
NA値がないことを確認してください。
#ダミーセットのNAを0に置き換えます
print(workingDummies.isna()。sum()。loc [workingDummies.isna()。sum()> 0] .sort_values(ascending = False))
データをトレーニングセットとテストセットに分割します。
#split特徴とsalePrice
salePriceClean = workingClean.SalePrice
homeFeaturesClean = workingClean.copy()。降下( "SalePrice"、軸= 1)
salePriceDummies = workingDummies.SalePrice
homeFeaturesDummies = workingDummies.copy()。降下( "SalePrice"、軸= 1 )
ここで、EDAの場合、連続機能とカテゴリ機能を別々に視覚化します。まず、すべての数値のヒストグラムのグリッドを作成する方法を次に示します。
#論争とカテゴリーに分割
workingNumeric = workingClean [['GarageYrBlt'、 'LotFrontage'、 'LotArea'、 'OverallCond'、 'YearBuilt'、 'YearRemodAdd'、 'MoSold'、 'GarageArea'、 'TotRmsAbvGrd'、 'GrLivArea'、 'BsmtUnfSF MSSubClass '、' YrSold '、' MiscVal '、' BsmtFinSF1 '、' BsmtFinSF2 '、' TotalBsmtSF '、' 1stFlrSF '、' 2ndFlrSF '、' LowQualFinSF '、' BsmtFullBath '、' BsmtHalfBath '、' FullBath ' 、 'BedroomAbvGr'、 'KitchenAbvGr'、 'Fireplaces'、 'GarageCars'、 'WoodDeckSF'、 'OpenPorchSF'、 'EnclosedPorch'、 '3SsnPorch'、 'ScreenPorch'、 'PoolArea'、 'OverallQual'、 'MasVnrArea']]
workingNumeric ['SalePrice'] = salePriceClean
ここで、pltでプロットします。
fig = plt.figure(figsize = [20,10])
#現在の軸を取得
= gca ax = fig.gca()
#ここでは、最後に説明したものに適用します…
workingNumeric.hist(ax = ax)
plt.subplots_adjust(hspace = 0.5)

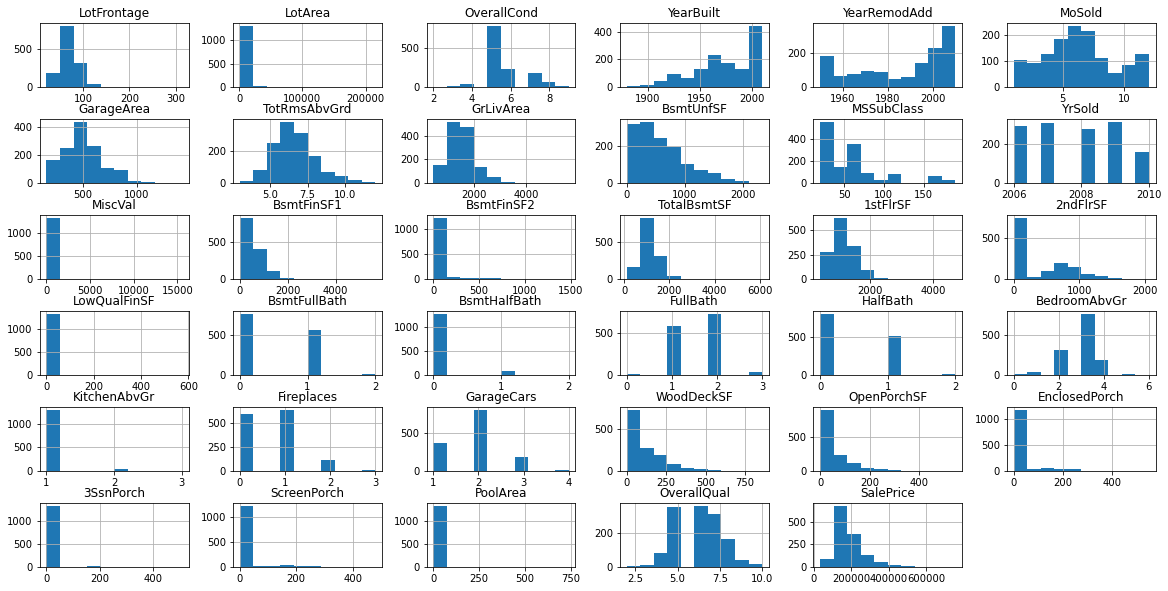
次に、これらの同じ機能の相関ヒートマップを確認できます。
rs = workingNumeric
d = pd.DataFrame(data = workingNumeric、columns = list(workingNumeric.columns))
#相関行列を計算します
corr = d.corr()
#上部三角形のマスクを生成する
マスク= np.triu(np.ones_like(CORR、DTYPE =ブール値))を
#matplotlibの図fを設定します。ax = plt.subplots(figsize =(11、9 ))
#カスタム発散カラーマップを生成します
cmap = sea.diverging_palette(230、20、as_cmap = True)
#マスクを使用してヒートマップを描画し、アスペクト比を修正します
sea.heatmap(corr、mask = mask、cmap = cmap、vmax = .3、center = 0、
square = True、linewidths = .5、cbar_kws = {"shrink": .5})
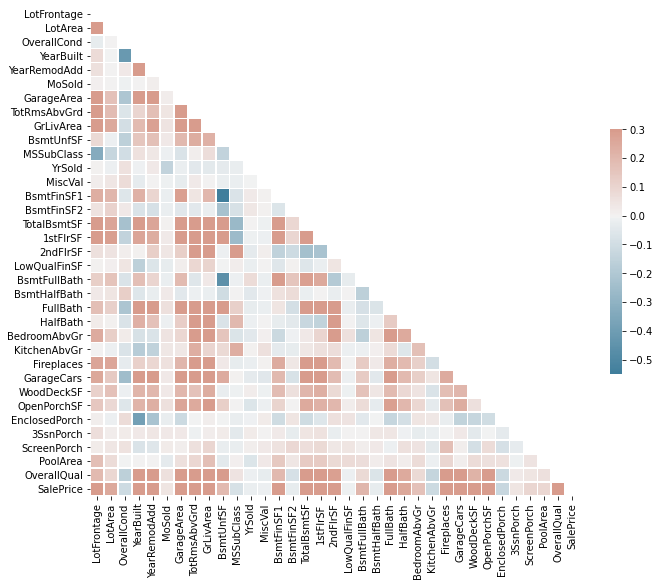
次に、これは、すべてのカテゴリ機能についてPythonで棒グラフのグリッドを生成する方法です。残念ながら、各プロットを個別に生成してプロットに配置する必要がある箱ひげ図コードとは異なり、ここでは最初のいくつかのコードを示します。
fig、axes = plt.subplots(13、3、figsize =(18、55 ))
sea.boxplot(ax = axis [0、0]、data = workingCategorical、x = 'MSZoning'、y = 'SalePrice')
sea.boxplot(ax = axis [0、1]、data = workingCategorical、x = 'SaleType'、y = 'SalePrice')
sea.boxplot(ax = axis [0、2]、data = workingCategorical、x = 'GarageType'、y = 'SalePrice')

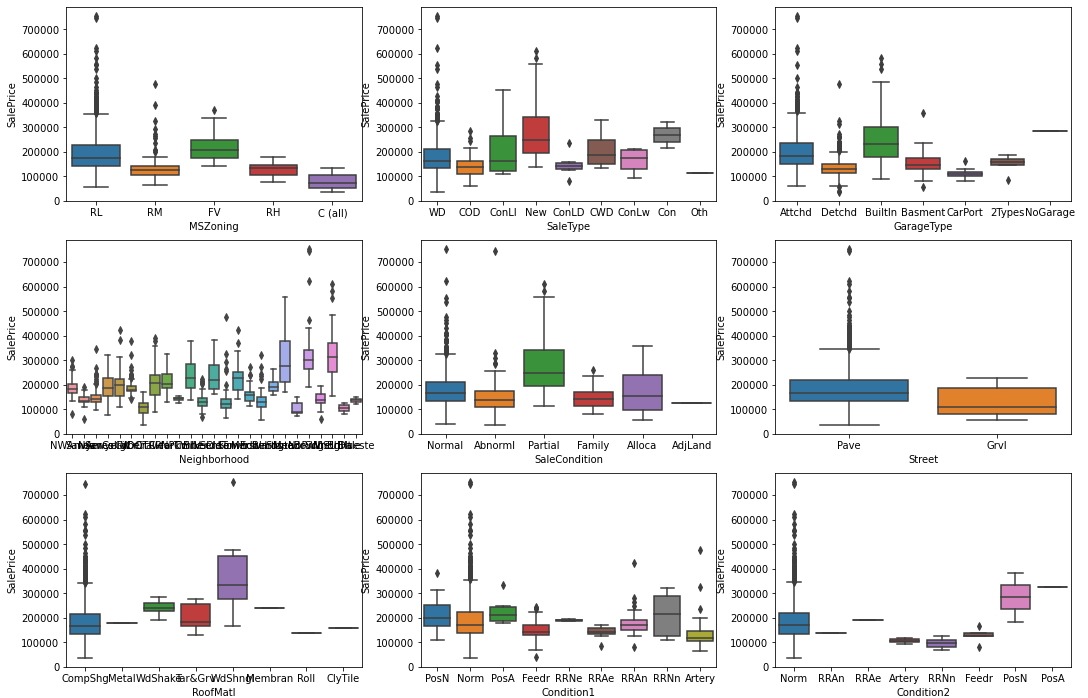
最後に、モデル構築に移ります。ここでは、ダミー化されたデータセットを使用していくつかの回帰モデルを実行する方法と、最適な結果、およびその情報をどのように使用するかを示します。
まず、グリッド検索を使用して最適なパラメーター(アルファ)を見つけるKNNモデル:
1
#KNN
knn_model = KNeighborsRegressor()
param_grid = { 'N_NEIGHBORS':np.arange(5、200、5)}
gsModelTrain = GridSearchCV(推定= knn_model、param_grid = param_grid、CV = 2)
gsModelTrain.fit(featuresDummiesTrain、priceDummiesTrain)
knn_model .set_params(** gsModelTrain.best_params_)
#fit to train data
knn_model.fit(featuresDummiesTrain、priceDummiesTrain)
#テストデータセットから実際の住宅価格と予測住宅価格を比較するスコアを取得します。
print( "r2テストスコア:"、r2_score(priceDummiesTest、knn_model.predict(featuresDummiesTest)))
print( "r2トレインスコア:"、r2_score(priceDummiesTrain、knn_model.predict(featuresDummiesTrain)))
trainRMSE = np.sqrt(mean_squared_error(y_true = priceDummiesTrain、y_pred = knn_model.predict(featuresDummiesTrain)))
testRMSE = np.sqrt(mean_squared_error(y_true = priceDummiesTest、y_pred = knn_model.predict(featuresDummiesTest)))
print( "Train RMSE:"、trainRMSE)
print( "Test RMSE:"、testRMSE)
結果!
r2テストスコア:0.6307760069201898
r2トレインスコア:0.7662448448900541
トレインRMSE:37918.53459536937
テストRMSE:48967.481488778656
ここで、Ridge()、Lasso、RandomForrestに対してこれとまったく同じことを行いますが、最適化されるパラメーターを変更します。これが私の最終結果です:
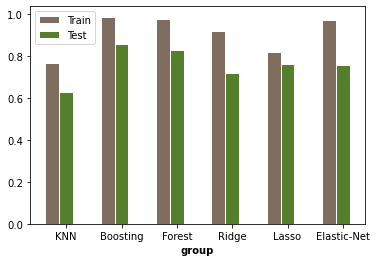
ランダムフォレストまたはブースティングモデルが最適であることがわかったので、次に、次のように、そのモデルから最も重要な機能を取得します。
rfModel.feature_importances_
feature_importances = pd.DataFrame(rfModel.feature_importances_、
index = featuresDummiesTrain.columns、
columns = ['importance'])。sort_values( 'importance'、ascending = False)
pd.set_option( "display.max_rows"、None、 "display.max_columns"、None)
print(feature_importances)
feature_importances.index [:10]
そしてこれが、Pythonを使用してこのモデルの最も重要な機能のリストを取得する方法です!
重要
OverallQual 5.559609e-01
GrLivArea 9.929112e-02
TotalBsmtSF 4.050054e-02
1stFlrSFの3.604577e-02
TotRmsAbvGrd 2.772576e-02
FullBath 2.693519e-02
BsmtFinSF1の2.064975e-02
GarageCars 1.915783e-02
2ndFlrSFの1.753713e-02
GarageArea 1.748563e -02
LotArea 1.219073e-02
YearBuilt 1.075511e-02
LotFrontage 7.270100e-03
YearRemodAdd 7.038709e-03
BsmtQual_Ex 5.726935e-03
OpenPorchSF 4.677578e-03
BsmtUnfSF 4.245650e-03
MoSold 3.397142e-03
OverseasCond 3.180477e-03
WoodDeckSF 2.865491e-03
KitchenQual_Gd 2.692117e-03
ExterQual_Ex 2.253200e-03
GarageType_Detchd 1.832978e-03
MSSubClass 1.808349e-03
BsmtFullBath 1.791505e-03
MSZoning_RM 1.781576e
ScreenPorch 1.679301e-03
YrSold 1.664580e-03
BsmtExposure_No 1.533721e-03
GarageFinish_Unf 1.514469e-03
MasVnrArea_1170.0 1.431316e-03
これで、家の全体的な品質とそのサイズが非常に重要であることがわかりましたが、完成したガレージやポーチでふるいにかけられているかどうかなどは基本的に無視できます。
この同じシステムを使用して、任意の数の機能を備えた任意のホームデータを評価できます。ここでの大きなポイントは、このリストの一番下にあるすべての機能を安全に無視できることです。そのため、住宅を販売または価格設定している場合、ほとんどの場合、それらを考慮する理由はありません。