脳活動から音声を解読できるAIモデル
このモデルは、793 語の語彙から最大 73% の上位 10 の精度で音声セグメントをデコードします。

Meta は、さまざまな分野での AI ツールの実用化にかなり長い間取り組んできました。そのMyoSuiteは、医療における AI によってもたらされるメリットの一例です。今回、同社は、病状を持つ人々を助けることができる新しい AI モデルを発表しました。このモデルは、脳活動の非侵襲的記録から音声を解読できます。
Meta は、3 秒間の脳活動から、モデルが 793 語の語彙から最大 73% のトップ 10 精度で対応する音声セグメントをデコードできると主張しています。
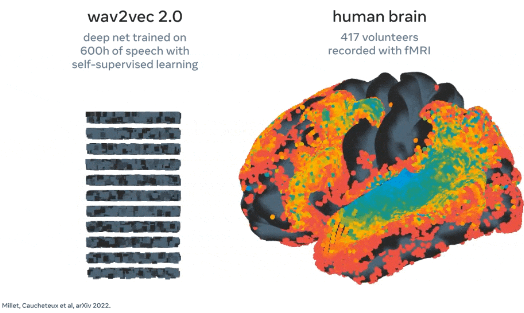
深層学習モデルは、対照学習でトレーニングされた後、非侵襲的な脳の記録と音声を調整するために使用されます。これを行うために、研究者は、オーディオブックを聞いているボランティアの脳内の音声の複雑な表現を識別するのに役立つオープンソースの学習モデルであるwave2vec 2.0を使用します。
「私たちは 2 つの非侵襲的技術に焦点を当てました: 脳波記録と脳磁図 (略して EEG と MEG) で、それぞれ神経活動によって誘発される電場と磁場の変動を測定します。実際には、両方のシステムで巨視的な脳活動の約 1,000 のスナップショットを撮ることができます。何百ものセンサーを使用して、毎秒。」
研究者は、4 つのオープンソースの EEG および MEG データセットを活用し、169 人の健康なボランティアがオーディオブックを聞いたり、英語とオランダ語で孤立した文章を聞いたりする 150 時間以上の録音を利用しました。次に、これらの EEG と MEG の記録を「脳」モデルに入力します。このモデルは、残差接続を備えた標準の深い畳み込みネットワークで構成されます。
アーキテクチャは、この脳モデルの出力を、参加者に提示された音声の深い表現に合わせることを学習します。トレーニング後、システムはゼロショット分類を実行します。「脳活動のスニペットが与えられると、その人が実際に聞いた新しいオーディオ クリップの大規模なプールから判断できます。そこから、アルゴリズムはその人が最も可能性が高い言葉を推測します
次のステップは、チームがこのモデルを拡張して、オーディオ クリップのプールを必要とせずに、脳の活動から音声を直接デコードできるかどうかを確認することです。
この論文は、このアプローチは大量の異種データのプルから恩恵を受け、小さなデータセットのデコードを改善するのに役立つ可能性があると結論付けています。アルゴリズムは、多くの個人や状態を含む大規模なデータセットで事前トレーニングされ、データがほとんどない新しい患者の脳活動の解読をサポートできます。
Meta Presented AI Model That Can Decode Speech from Brain Activity